Как подготовить резюме ML-инженера и повысить шанс получить оффер
Получить оффер на ML-позицию — это не магия и не удача, а воронка отбора. Кандидат проходит несколько этапов: просмотр резюме, HR-скрининг, техническое собеседование, лайвкодинг, обсуждение опыта и финальное решение команды. На каждом шаге часть кандидатов отсеивается, поэтому подготовка к собеседованию в Machine Learning начинается не с алгоритмов, а с сильного резюме.
Этот материал подготовлен по мотивам выпуска рубрики #MLСобес с Димой Савелко — LLM Engineer в Tochka Bank, DS-ментором и магистрантом AI Talent Hub. В рубрике эксперты Хаба разбирают, как подготовиться к собеседованию на позиции ML Engineer, Data Scientist и LLM Engineer: от резюме и HR-скрининга до технических интервью, лайвкодинга и финального оффера.
В первом выпуске нового сезона фокус — на самом верхе карьерной воронки: как написать резюме, которое заметят рекрутеры, пройдут ATS-системы и захотят обсудить на техническом интервью.В новом сезоне рубрики #MLСобес эксперты AI Talent Hub разбирают, как подготовиться к собеседованию на ML Engineer, Data Scientist и LLM Engineer позиции. В первом выпуске фокус — на самом верхе карьерной воронки: как написать резюме, которое заметят рекрутеры, пройдут ATS-системы и захотят обсудить на техническом интервью.
В первом выпуске нового сезона фокус — на самом верхе карьерной воронки: как написать резюме, которое заметят рекрутеры, пройдут ATS-системы и захотят обсудить на техническом интервью.В новом сезоне рубрики #MLСобес эксперты AI Talent Hub разбирают, как подготовиться к собеседованию на ML Engineer, Data Scientist и LLM Engineer позиции. В первом выпуске фокус — на самом верхе карьерной воронки: как написать резюме, которое заметят рекрутеры, пройдут ATS-системы и захотят обсудить на техническом интервью.
Оффер — это воронка, а резюме открывает вход в неё

Путь к офферу обычно выглядит примерно так:
около 1000 просмотров резюме → около 100 приглашений на HR-скрининг → 10–15 технических интервью → 1 финальный оффер.
Эти цифры условные, но они хорошо показывают механику найма. Если резюме не даёт конверсии в первый звонок, кандидат просто не доходит до технического собеседования. Поэтому задача соискателя — не просто «откликнуться на вакансии», а повысить конверсию на каждом этапе: от резюме до финального интервью.
Для ML-специалиста это особенно важно. На рынке много кандидатов, которые пишут в резюме одинаковые формулировки: «обучал модели», «работал с данными», «участвовал в разработке». Но такие фразы почти ничего не говорят о реальном уровне кандидата, его грейде и пользе для бизнеса.
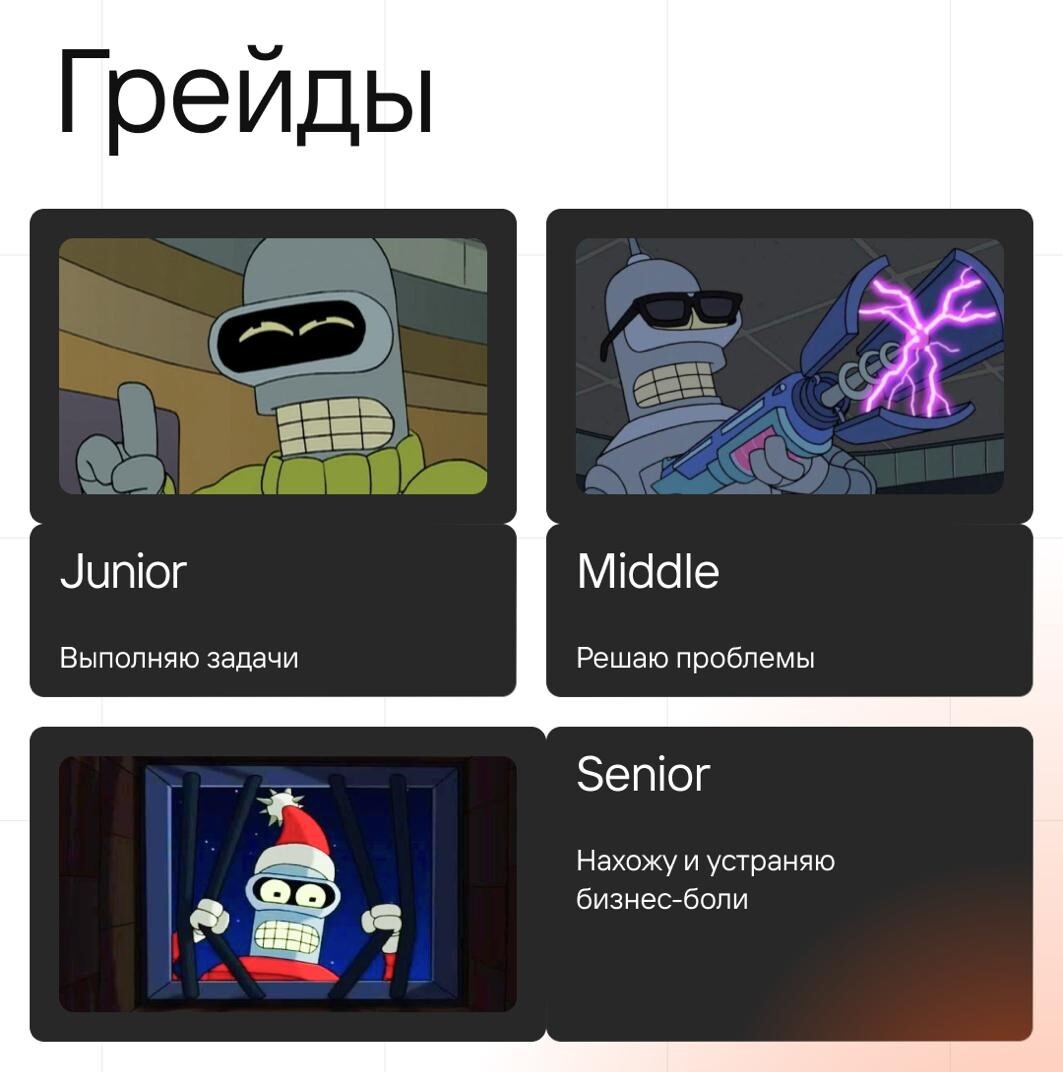
Сначала определите свой грейд
Перед тем как писать резюме ML-инженера или Data Scientist, важно честно определить свой грейд. Грейд — это не просто количество лет опыта, а уровень ответственности, который специалист реально способен брать на себя.
Junior — получает задачу, уточняет детали и выполняет её под руководством. На этом уровне важны обучаемость, аккуратность, понимание базовых ML-подходов, умение работать с кодом, данными и простыми моделями.
Middle — получает проблему, самостоятельно предлагает решение и доводит его до результата. Такой специалист умеет выбирать подходы, строить пайплайн, оценивать качество модели, анализировать ошибки и объяснять свои решения команде.
Senior — сам находит проблемы, которые мешают бизнесу или продукту расти, предлагает архитектурные и процессные изменения, влияет на стратегию ML-разработки. Здесь важны не только хард-скиллы, но и системное мышление, техническое лидерство, понимание бизнеса и умение принимать решения в условиях неопределённости.
Ошибка многих кандидатов — продавать себя не в тот грейд. Если человек подаётся на Senior ML Engineer, но в резюме пишет только про «написание скриптов» и отдельные эксперименты, у рекрутера и техлида быстро возникает вопрос к уровню самостоятельности. Если Junior пытается описать себя как архитектора всей ML-системы, это почти наверняка вскроется на первом техническом интервью.
Хорошее резюме не должно завышать опыт, но должно показывать его максимально сильно. Честность и сильная упаковка здесь работают вместе.
Как описывать опыт в резюме ML-специалиста
Главная ошибка в резюме — писать опыт через процесс, а не через результат. Формулировки вроде «занимался разработкой», «участвовал в проекте», «обучал модели» звучат слишком общо. Они не показывают, какую задачу решал кандидат, какие инструменты использовал и к какому эффекту пришёл.
Для описания опыта лучше использовать формулу:
Action + Tool + Result
То есть: что вы сделали, с помощью какого инструмента или подхода, и какой результат получили.
Плохо: Обучал модели для классификации текстов.
Лучше: Внедрил BERT-модель для классификации обращений в техподдержку, что снизило нагрузку на операторов на 30%.
Во втором варианте сразу видно три важных элемента: действие, технология и измеримый результат. Именно такие формулировки помогают резюме ML-инженера выглядеть убедительно для рекрутера, hiring manager и технического интервьюера.
Если точных цифр нет, результат всё равно стоит оценить. Это может быть снижение времени обработки, рост точности модели, ускорение пайплайна, сокращение ручной работы, улучшение метрики качества, экономия ресурсов команды или бизнеса. Работодателю важно понимать не только то, какой код вы писали, но и какую проблему этот код помог решить.
Как пройти ATS и не потеряться до встречи с рекрутером
В крупных компаниях резюме часто сначала обрабатывают ATS-системы — автоматические системы подбора персонала. Они помогают рекрутерам фильтровать отклики и искать ключевые слова, которые совпадают с требованиями вакансии.
Если в вакансии указаны RAG, Docker, Kubernetes, PyTorch, MLflow, Airflow, LLM, NLP, Computer Vision, а в резюме этих слов нет, система может просто не поднять кандидата выше в выдаче. Даже если человек реально владеет этими инструментами.
Поэтому перед откликом стоит адаптировать резюме под конкретную ML-вакансию. Не нужно бездумно добавлять все популярные технологии подряд. Но если вы действительно работали с указанными инструментами, они должны быть отражены в резюме: в описании проектов, стека, навыков или достижений.

Для SEO и для реального найма здесь работает одно и то же правило: важные ключевые слова должны быть в тексте, но выглядеть естественно. Резюме должно быть читаемым для человека и понятным для автоматической системы.
Резюме читают быстро: структура важнее объёма
Рекрутер не изучает резюме как дипломную работу. Обычно у него есть несколько секунд, чтобы понять: кто вы, на какую позицию претендуете, что умеете и почему с вами стоит поговорить.
Поэтому резюме ML Engineer или Data Scientist должно быть структурным. За один скролл должно быть понятно:
>> кто вы по роли и грейду;
>> какой у вас основной стек;
>> с какими задачами вы работали;
>> какие результаты получили;
>> какие проекты или достижения подтверждают ваш уровень.
Лучше всего работают короткие буллеты, выделение ключевого стека и метрик, понятные названия проектов, аккуратные блоки и «воздух» в оформлении. Стена текста снижает шанс, что опыт вообще прочитают.
Soft skills лучше показывать через действия
Отдельный раздел «о себе» часто превращается в набор пустых слов: коммуникабельный, стрессоустойчивый, ответственный, командный игрок. Такие формулировки почти не помогают кандидату.
Soft skills лучше показывать через конкретные ситуации:
плохо: «Коммуникабельный»
лучше: Согласовал с заказчиком изменение целевой метрики, чтобы команда успела выпустить MVP в срок»
лучше: Согласовал с заказчиком изменение целевой метрики, чтобы команда успела выпустить MVP в срок»
плохо: «Умею работать в команде»
лучше: «Менторил двух стажёров по ML-проекту: оба успешно прошли испытательный срок и подключились к продуктовым задачам»
лучше: «Менторил двух стажёров по ML-проекту: оба успешно прошли испытательный срок и подключились к продуктовым задачам»
Такой подход показывает не абстрактное качество, а реальное поведение кандидата в рабочем контексте.
Что важно запомнить перед откликом на ML-вакансию
Сильное резюме для ML-собеседования должно отвечать на три вопроса: какой у вас уровень, какие задачи вы умеете решать и какую пользу уже приносили проектам или бизнесу.
Перед отправкой резюме проверьте:
— соответствует ли описание опыта вашему грейду;
— есть ли в резюме ключевые слова из вакансии;
— описаны ли проекты через действие, инструмент и результат;
— видны ли метрики, бизнес-эффект или технический эффект;
— можно ли понять вашу ценность за один быстрый просмотр.
Резюме — это первый фильтр в найме ML-специалистов. Если оно работает плохо, кандидат может не дойти до этапа, где сможет показать реальные знания: технического интервью, лайвкодинга или обсуждения проектов.
В следующих материалах рубрики #MLСобес разберём хард-скиллы для ML-собеседований: зачем на интервью дают алгоритмические задачи, почему лайвкодинг всё ещё используют при найме ML-инженеров и как пройти этот этап без лишнего стресса.